$cat./references
An AI Engineering Reference. Every post analyzes production code patterns, benchmarks, and architecture decisions. Snippets are verified. Intelligence is measured.

Speculators: Engineering the Unified Speculative Decoding Library for Production LLM Inference
Deep dive into the vLLM project's Speculators library — covering Eagle3, DFlash, P-EAGLE, and MTP algorithm support, offline/online training pipelines, FlexAttention integration, and production deployment patterns.
Read referenceSpeculators: Engineering the Unified Speculative Decoding Library for Production LLM Inference
Deep dive into the vLLM project's Speculators library — covering Eagle3, DFlash, P-EAGLE, and MTP algorithm support, offline/online training pipelines, FlexAttention integration, and production deployment patterns.

The Hidden Architecture of LLM Routing: From if-else to Production Gateways
An engineering essay tracing LLM routing from naive if-else chains through learned complexity routers and model cascades to full production gateways — with cost data, code examples, and architectural tradeoffs at each stage.

Production Debugging & Root Cause Analysis of AI System Failures
Production AI debugging covers agent state corruption via a Python mutable default and OpenAI agent SDK examples, memory leaks including phantom leaks…
Prompt Caching in Production: Engineering Patterns Across Four Providers
A comparative engineering analysis of prompt caching across OpenAI, Anthropic, Google, and DeepSeek — provider mechanics, cache-aware architecture patterns, cost modeling, and empirical latency/cost data from production deployments.

Agent Loop Production Hardening: Circuit Breakers, Token Budgets, and Graceful Degradation
An engineering deep dive on production hardening for autonomous agent loops — token-aware rate limiting, circuit breaker state machines, budget-aware runtimes, and empirical failure data from production deployments of LLM agents.
AI Code Review in Production: Architecture Patterns, False Positive Benchmarks, and Engineering Tradeoffs
An engineering analysis of LLM-based code review in production — comparing single-pass vs multi-agent architectures, benchmark results from CR-Bench and c-CRAB, false positive rates across strategies, and a decision framework for when and how to deploy AI review agents.

Production Prompt Caching for LLM APIs: Provider Comparison, Architecture Patterns, and Empirical Hit-Rate Analysis
An engineering deep dive comparing prompt caching across OpenAI, Anthropic, Google, and DeepSeek — KV cache mechanics, cache breakpoint strategies, cache hit rate optimization patterns, and production latency/cost benchmarks from real deployments.

Automated Test Generation with LLMs: Production Patterns and Empirical Quality Benchmarks
An engineering analysis of LLM-based unit test generation — coverage benchmarks across studies, prompting strategies, iterative refinement architectures, CI/CD integration patterns, and the production gap between academic results and real-world reliability.

The Week in Coding Intelligence: July 6–12, 2026
xgrammar (8-15%) adopted by OpenAI, vLLM, SGLang. Reliability Gate pattern (Pydantic). PALM 79% coverage, iterative refinement (testgen-iterative) 92%…
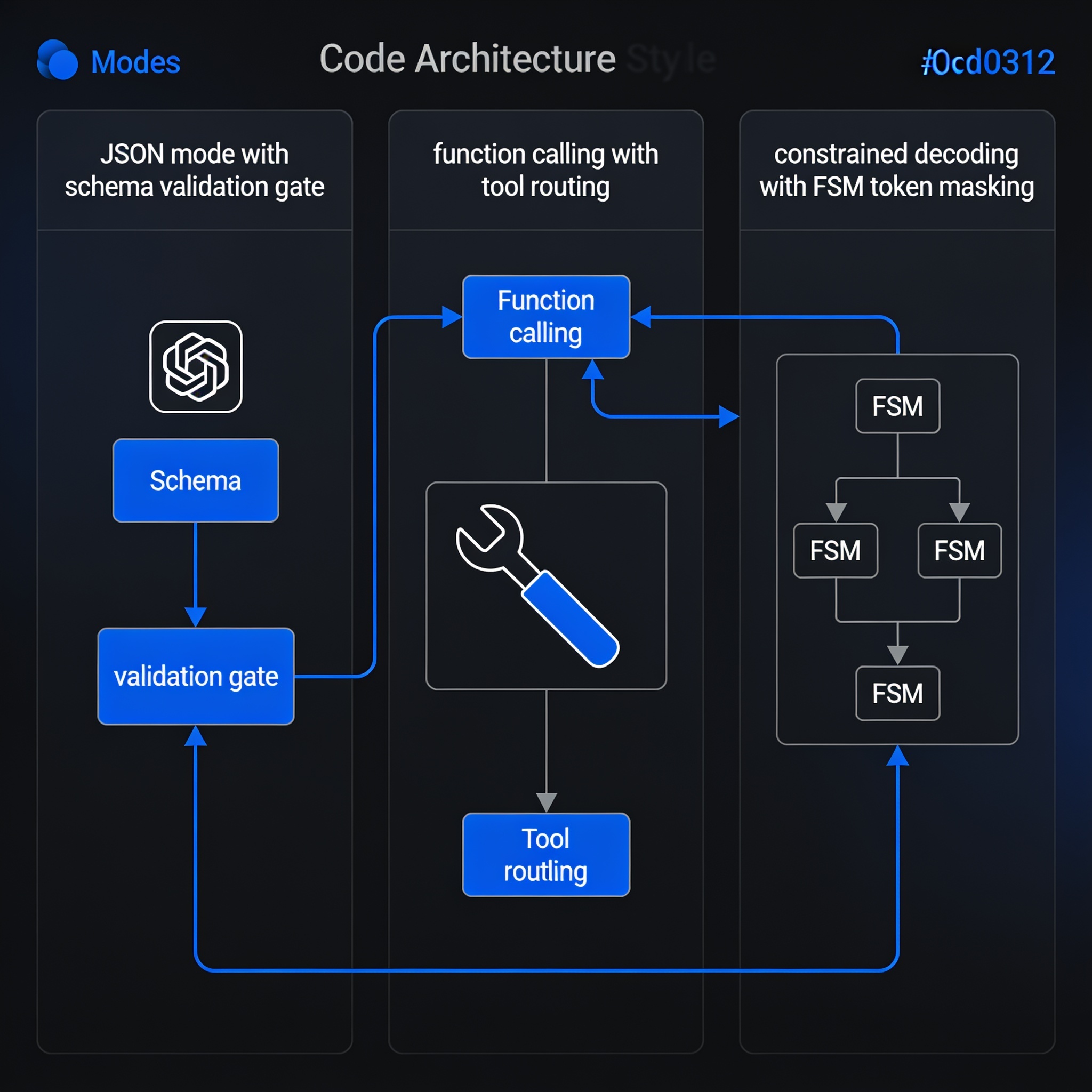
Structured Output in Production: A Comparative Engineering Analysis of JSON Mode, Function Calling, and Constrained Decoding
This article compares three structured data extraction methods from LLMs—JSON mode, function/tool calling, and constrained decoding—along parse…

Durable Execution Patterns for Long-Running AI Agents
An engineering analysis of state persistence for AI agents spanning minutes to hours — checkpoint graphs, event-sourced state machines, compensation sagas, and the architectural tradeoffs behind 99.97% execution reliability at 10K+ runs.

Quantization-Aware Development: How Precision Shapes AI Code Generation Quality
An empirical analysis of how FP16, INT8, INT4, and NF4 quantization levels affect LLM code generation — when precision matters, when it's noise, and how to choose the right quantization tier for your production pipeline.
Agent Execution Sandboxes: Production Architecture for Safe AI-Generated Code
A deep-dive on sandbox architectures for AI agent code execution — container isolation vs gVisor vs Firecracker microVMs, network egress controls, OWASP threat modeling, and production deployment patterns with benchmark data.

Structured Verification Loops for Agentic Code Generation
An engineering analysis of verification-augmented code generation — compile-time, runtime, and static analysis feedback loops that lift code agent success rates from 57% to 89% in production benchmarks.

Building a Structured Output Verification Harness for LLM Pipelines
A production architecture for verifying LLM structured outputs using typed validation, self-consistency checks, and cascading repair strategies. Schema enforcement at the harness layer, not the prompt layer.
The Self-Generated Item Gap: When AI Coding Systems Can't Validate Their Own Technical Claims
A 0% solve rate on self-generated corpus items vs 92.1% on third-party SWE-bench items reveals a structural blind spot in AI code intelligence evaluation. Analysis of the gap between writing about code and writing code.
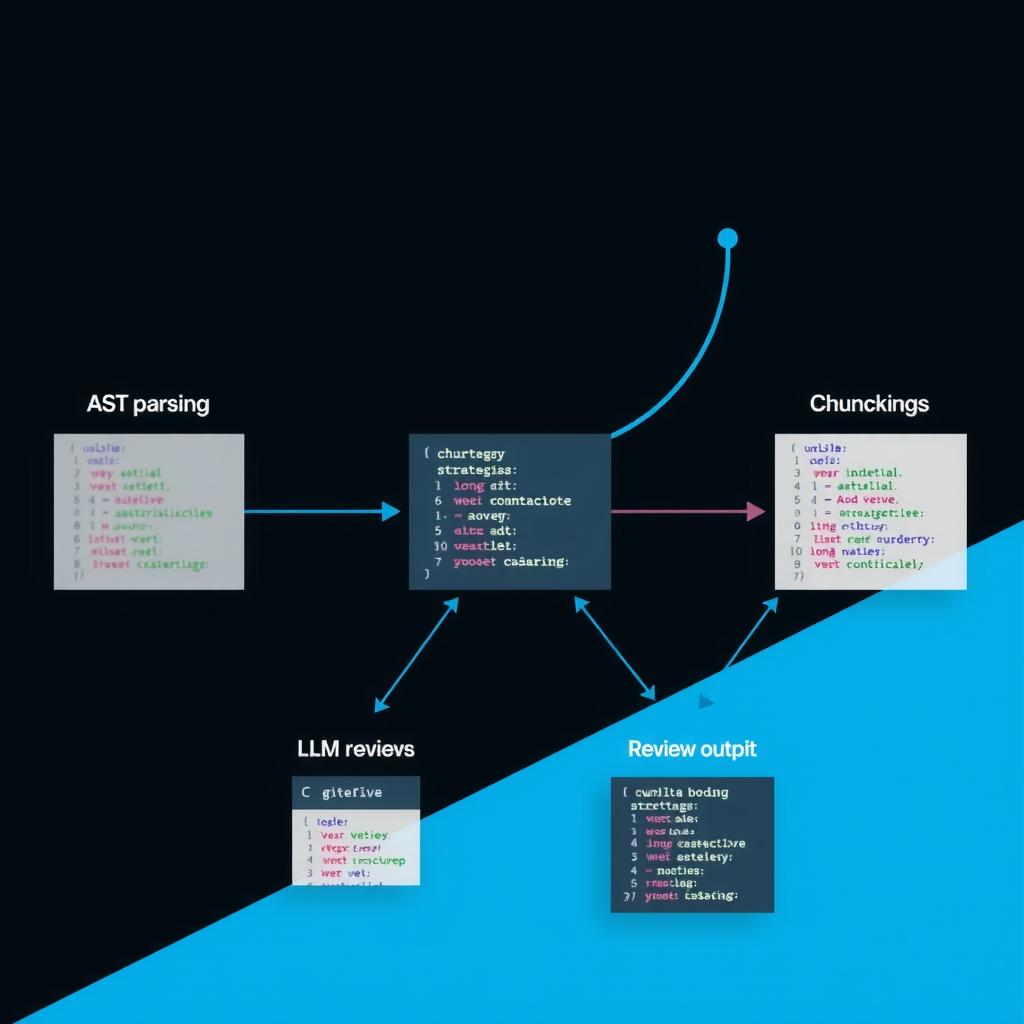
Building a Structured Diff Analysis Pipeline for PR Review — A Weekend Build Log
A weekend project building a pipeline that ingests git diffs, enriches them with AST context, and produces ranked review comments — with benchmarks comparing chunking strategies across three models.
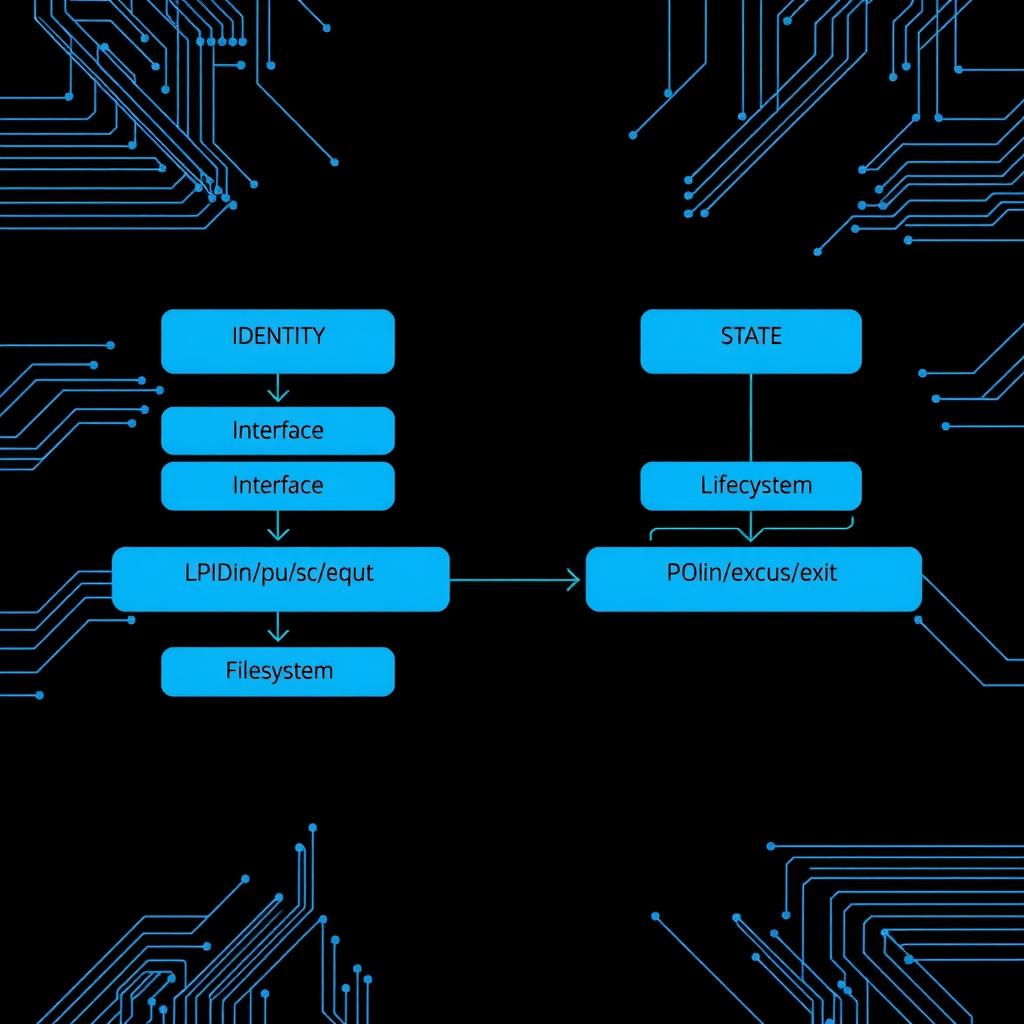
Quine: LLM Agents as Native POSIX Processes — A Systems Architecture Analysis
Deep analysis of the Quine architecture (arXiv:2603.18030) that maps LLM agents to native POSIX processes — PID as identity, fork/exec as lifecycle, streams as interface — and what it reveals about the limits of OS process semantics for cognition.
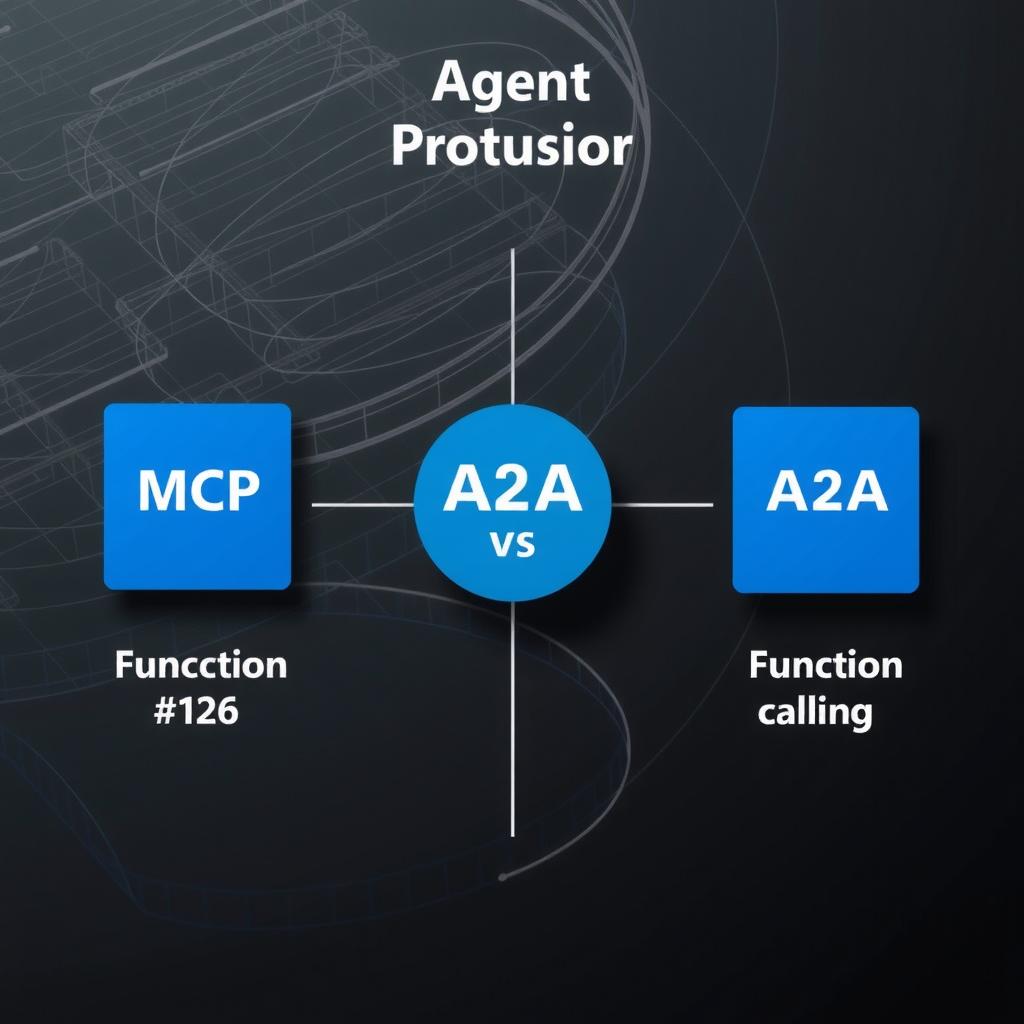
MCP vs A2A vs Function Calling: The Agent Protocol Landscape in 2026
Technical comparison of Model Context Protocol (MCP), Agent-to-Agent Protocol (A2A), and traditional function calling. Architecture, adoption data, security patterns, and decision framework for choosing the right agent communication protocol.
Aider Deep Dive: Architecture, Benchmarks, and Engineering Tradeoffs (2026)
A comprehensive engineering review of Aider — the open-source CLI coding agent — covering its tree-sitter repo mapping, dual-model architect/editor architecture, benchmark performance, and where it fits in an AI engineering stack.

Daily AI Briefing: June 30, 2026
South Korea's $576B plan (10 GW data center) and Qualcomm's $3.9B Modular buy attack NVIDIA's CUDA moat. Governance: GPT-5.6 Sol, with enhanced…
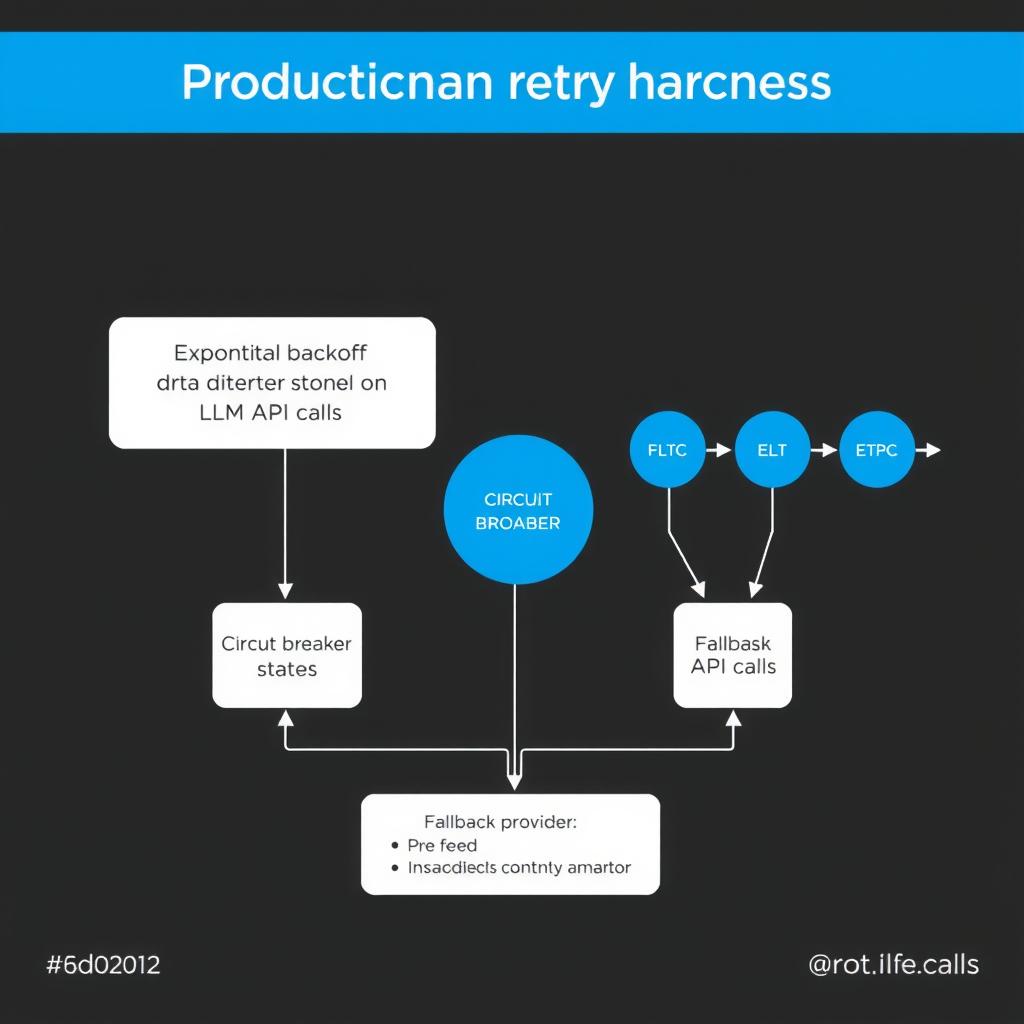
Building a Production Retry Harness for LLM API Calls
A step-by-step tutorial on implementing resilient LLM API calls with exponential backoff, jitter, circuit breakers, and fallback providers — with production-ready Python code.

The Self-Correction Ceiling: Why Agentic Code Repair Hits Diminishing Returns at Three Iterations
Studies confirm a three-iteration wall: 7B models peak at 56% (from 38% initial) then decline, larger models hit 74% (from 62%). Bottlenecks:…

The Week in AI-Assisted Development: June 22–28, 2026
TypeScript 7.0 RC delivers a 10x faster Go-native compiler, MCP crosses 97M monthly downloads, SWE-bench Verified approaches saturation, and the inference engine landscape consolidates around three winners.
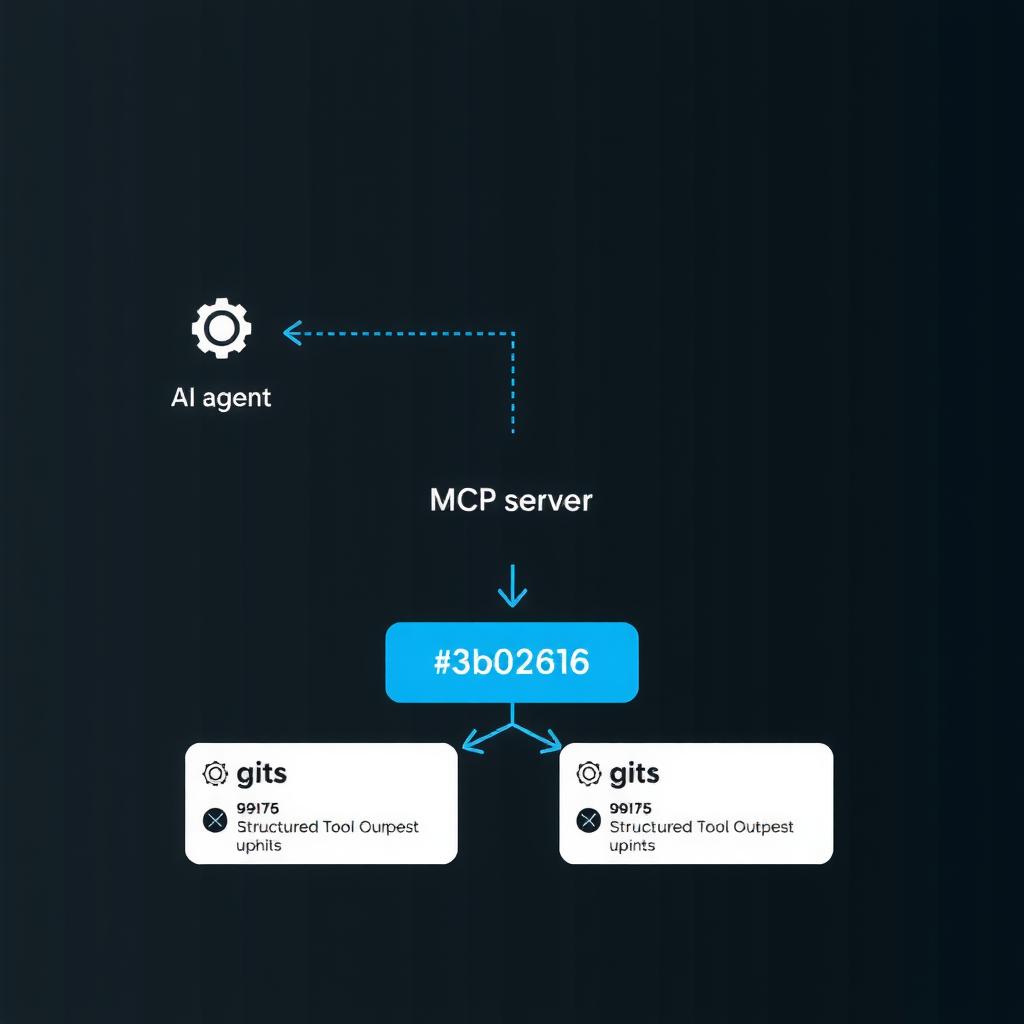
Building an MCP Server for Repository Intelligence — A Weekend Build Log
A structured weekend project building a Model Context Protocol server that exposes git history, code structure, and dependency analysis as MCP tools — with benchmarks showing 40-80% latency reduction over shell-based alternatives.
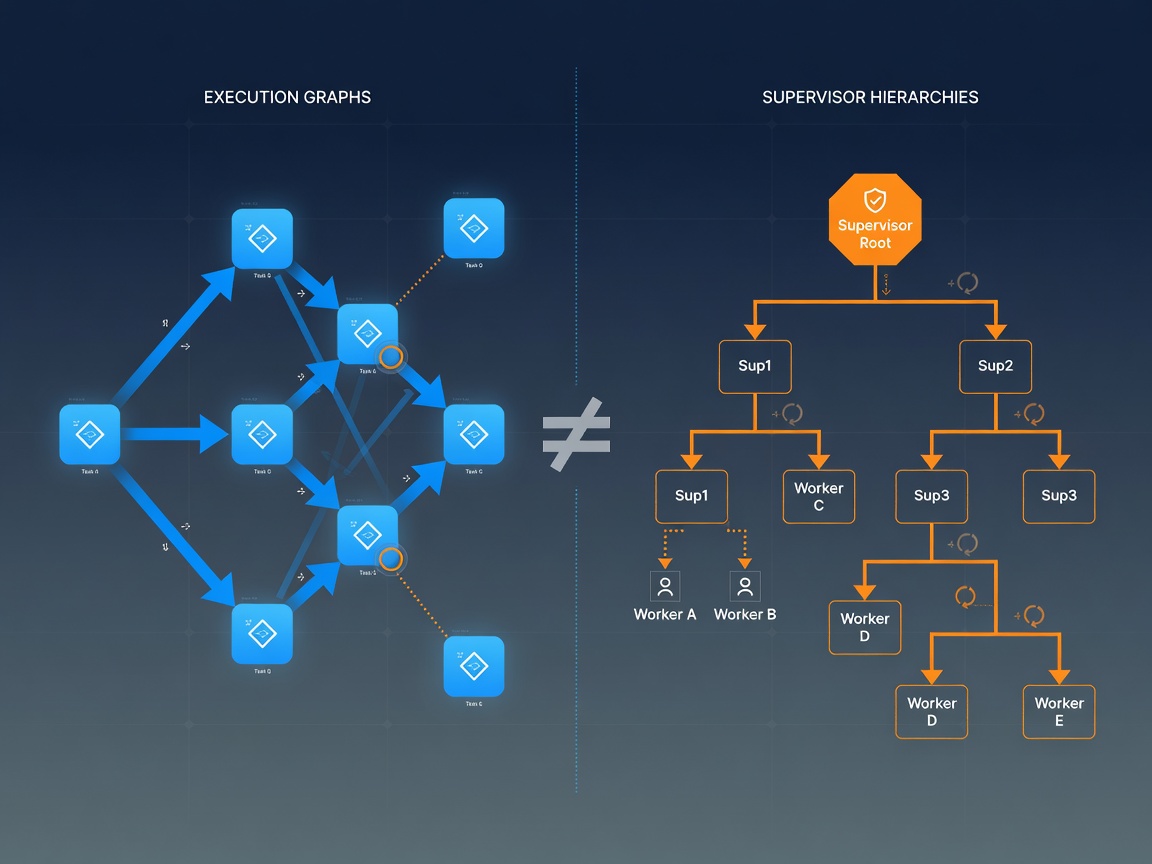
Execution Graphs vs. Supervisor Hierarchies: A Tradeoff Analysis of Agent Orchestration Architectures
A deep-dive comparison of the two dominant paradigms for orchestrating multi-agent systems in production — state-machine graphs and supervisor hierarchies — with decision criteria backed by empirical evidence.

Five AI Agent Production Failures and the Traces That Catch Them
A root-cause analysis of the five most common AI agent production failures in 2026 — runaway loops, hallucinated actions, context window exhaustion, tool misuse cascades, and silent degradation — with trace-driven diagnosis methodology drawn from the TraceElephant benchmark, the PROBE recovery framework, and enterprise production postmortems.
Terminal-Bench v2.1: A Benchmark Study of CLI-Based AI Agent Coding
An empirical analysis of Terminal-Bench v2.1 — 89 curated CLI tasks across 13 verified model+agent combinations. Claude Fable 5 leads at 88.0% (Codex CLI GPT-5.5 at 83.4%), with a 27.9-point gap between top and bottom entries. We examine task taxonomy, confidence intervals, harness effects, and the inference-time scaling frontier.

The Three-Layer Architecture of Production Agent Harnesses
A deep analysis of the emerging framework-harness-platform stack powering production AI agents in 2026, based on real system architectures from Cloudflare Flue, Microsoft Agent Framework, and the MBZUAI Claude Code study.

Designing Distributed Observability Infrastructure for LLM-Powered Systems
A production architecture for LLM observability: distributed tracing with OTel GenAI semantic conventions, span-based cost attribution, latency profiling across inference stacks, and the four-layer monitoring topology that powers 10K+ request-per-second AI systems.

The Stateful Agent Paradox: Engineering Patterns for Context and State in Production AI Systems
A deep analysis of the fundamental tension between stateless scalability and stateful capability in production AI agents — and the six engineering patterns that reconcile them.
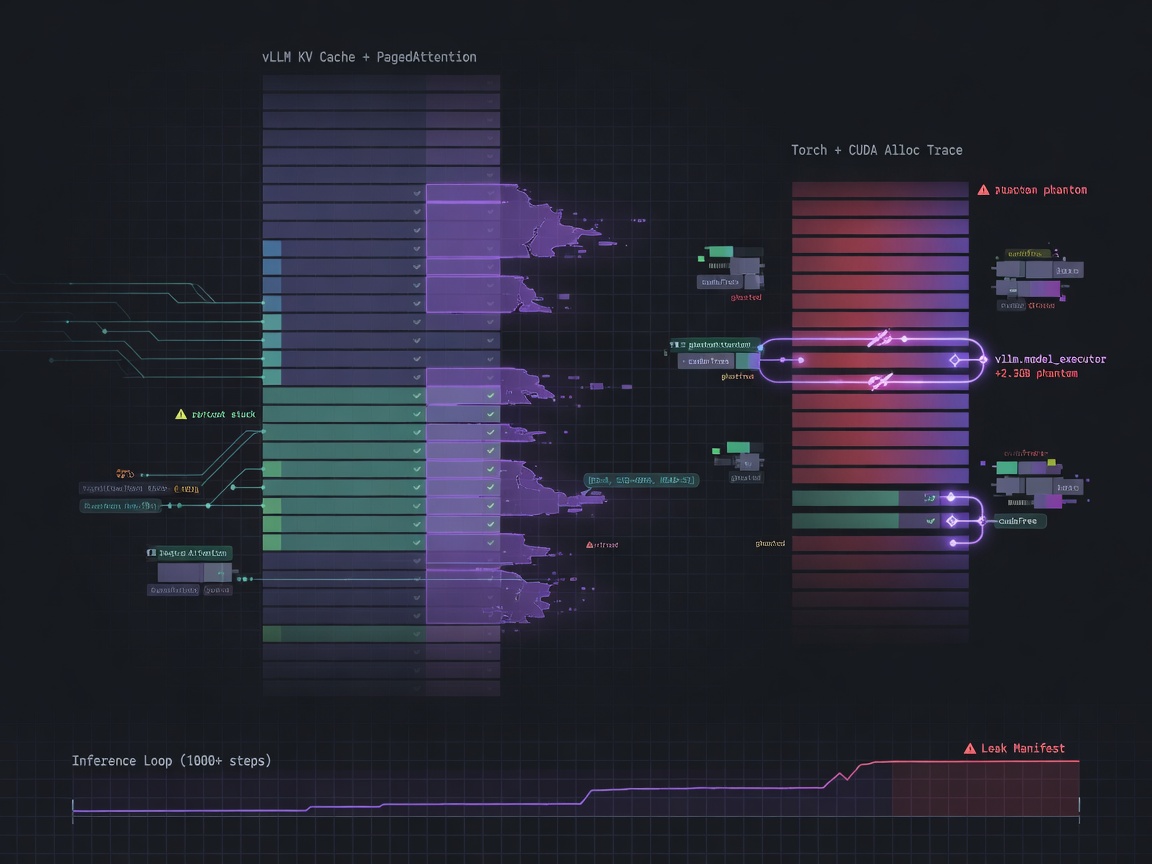
When Heaps Lie: Debugging Phantom Memory Leaks in vLLM Production
A systematic root cause analysis of three real vLLM production memory failures — how malloc profiling, scheduler tracing, and KV cache fragmentation analysis revealed bugs that standard monitoring could not detect.

Agent Evaluation Harness Architecture: Building Systematic Testing Infrastructure for AI Agents
Architecture patterns for production-grade agent evaluation harnesses: eval dataset design, LLM-as-judge pipelines, trajectory scoring, regression gates, and CI/CD integration. With real metrics from production deployments.

MCP Server Infrastructure: Production Patterns for Agent Tool Serving at Scale
Why MCP servers break in production — context window overload, security vulnerabilities, error handling gaps, and architecture patterns that keep tool serving reliable at scale.

Multi-Modal Inference Architecture: Serving Vision, Audio, and Text at Scale
A production architecture deep dive on multi-modal LLM serving — adapter vs early fusion vs unified architectures, EPD disaggregation for vision encoders, GPU memory strategies across modalities, and the gateway patterns that unify text, image, and audio inference.

LLM Router Architecture — Production Routing for Multi-Model Systems
Deep engineering analysis of LLM routing systems in production — embedding-based classifiers, cascading strategies, fallback topologies, and the gateway architectures that power 5K+ RPS routing with microsecond overhead.

Debugging EngineDeadError in vLLM — A Production Postmortem
Root cause analysis of vLLM EngineDeadError crashes under high concurrency on 8×B200 — tracing from 'Worker died unexpectedly' through dmesg to a divide-by-zero in FlashInfer's prefill kernel. Includes a systematic triage framework for LLM inference server failures.

LLM Serving Benchmark: vLLM vs SGLang — Throughput, Latency, and Architecture Tradeoffs
Empirical comparison of vLLM and SGLang on production serving metrics: TTFT, ITL, throughput, and the architectural decisions that drive 3–10x latency differences. Full methodology disclosed.

Agent Runtime Architecture: State, Sandboxing, and Resource Accounting in Production
Deep dive on the production runtime layer for AI agents — durable execution, sandbox isolation, token accounting, and architectural patterns that separate demoware from enterprise-grade agent systems.

Streaming Architecture for Large-Scale LLM Inference
A deep dive into production streaming patterns for LLM inference: SSE vs WebSocket vs gRPC, backpressure strategies, reverse proxy pitfalls, and the architectures that keep token delivery fast at scale.

Cleaning Up ripgrep's README: Removing Shell Prompt Prefixes from Code Blocks
A 41-line documentation fix in BurntSushi/ripgrep — removing `$ ` prefixes from README code blocks for cleaner copy-paste. PR #3437. Why shell prompts in documentation create friction for users.

Prompt Caching in Production: Architecture Patterns for AI Systems
An engineering deep dive on the four caching layers for LLM inference — KV/prefix caching, prompt caching, semantic caching, and exact-response caching — with architecture patterns, provider pricing analysis, and production deployment strategies.
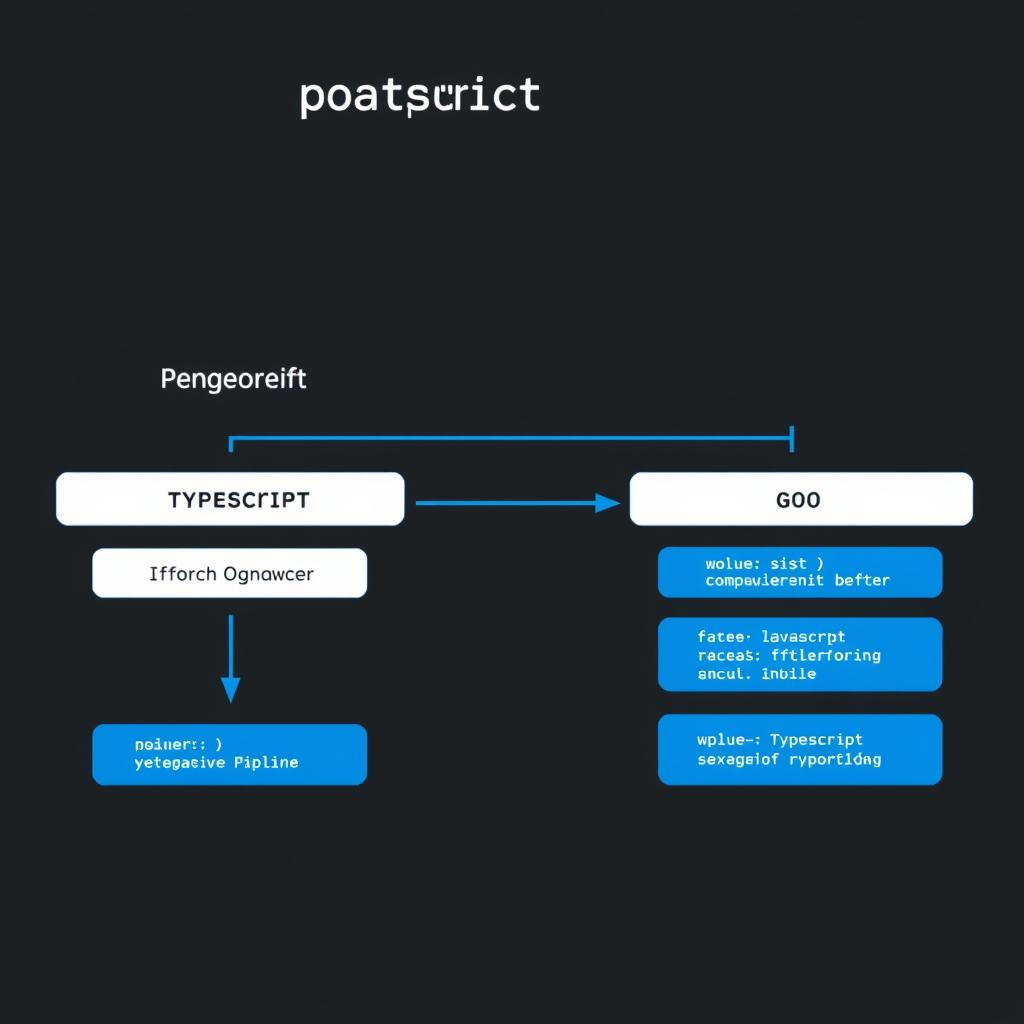
TypeScript is in Maintenance Mode: What the Go Rewrite Means for Production Systems
TypeScript 6.0 is the last JavaScript-based release. The compiler is being rewritten in Go, the JS codebase is in maintenance mode, and most open PRs will be auto-closed. What this means for production systems, tool authors, and the TypeScript contribution model.

State Corruption in Multi-Turn Agent Systems: A Forensic Debugging Guide
A systematic forensic approach to debugging state corruption in multi-turn agent systems — taxonomy, detection patterns, causal tracing, and production instrumentation based on 847 incidents and 13,602 open-source repository issues.
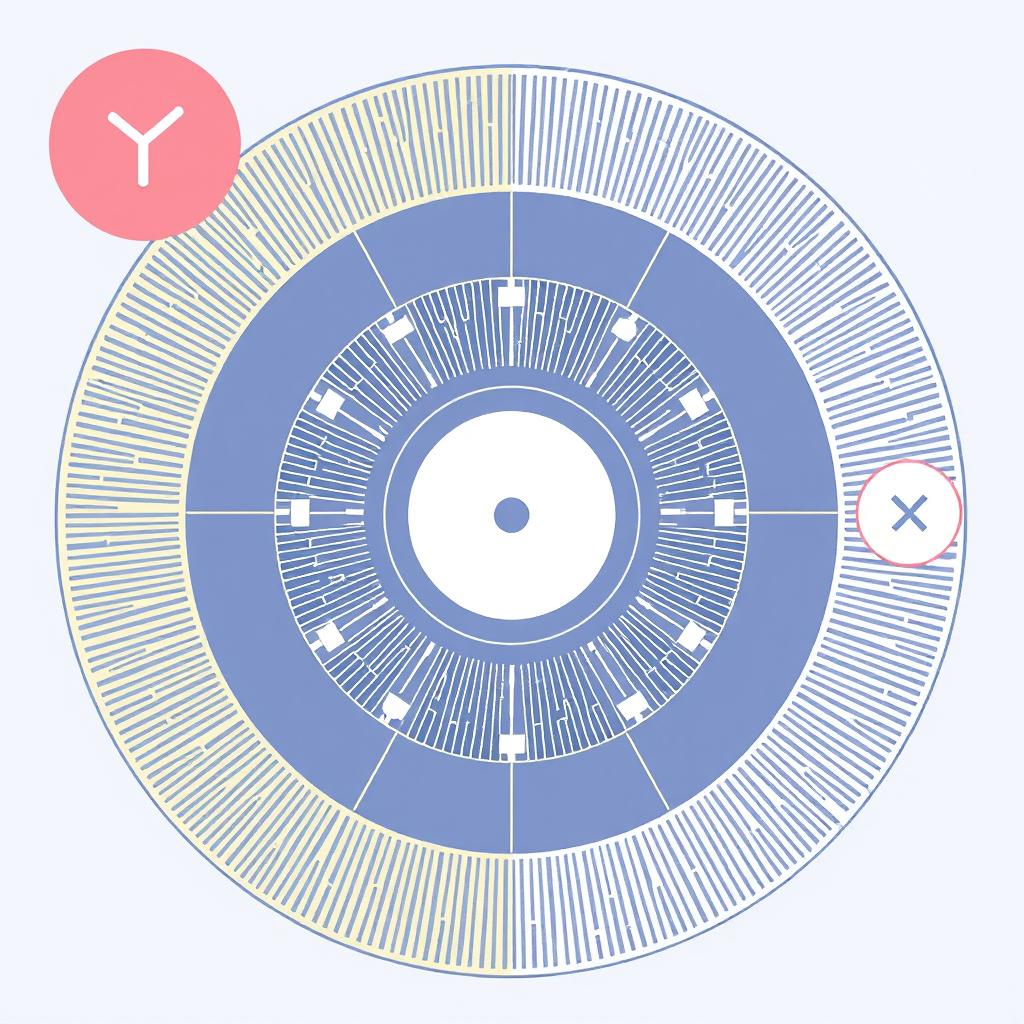
Function-Calling Benchmarks in 2026: What They Actually Measure
A comparative analysis of BFCL v3/v4, tau-bench, MCP-Atlas, FinTrace, and what their differing results reveal about production function-calling reliability.
The Architecture of Tool-Use in Agent Systems
Deep dive on how tool-use actually works in production agent systems: schema design, execution patterns, MCP protocol architecture, deferred loading, programmatic orchestration, and empirical findings from 856 MCP tools.
Event-Driven Architecture for Multi-Agent Systems: Production Patterns
A deep dive into event-driven architecture patterns for multi-agent AI systems — event chaining, fan-out, saga orchestration, and production deployment considerations.

TypeScript #25083: Non-Identifier Enum Keys in Computed Type Properties
A 3-line fix to isLateBindableAST() that allows Type['3x14'] bracket access as computed property names in type literals — fixing a 7-year-old enum correctness bug.

Compound Engineering: The 80/20 Rule That Changes AI Code Quality
Deep analysis of Every Inc's Compound Engineering methodology — why spending 80% of time on planning and review produces higher quality AI-generated code than the common prompt-burst approach.
One Typo, Two Years: Fixing a JSDoc Grammar Error in TypeScript
A one-character grammar fix in TypeScript's lib.d.ts — 'returns a undefined' → 'returns undefined'. PR #63525. Why JSDoc grammar matters in the most-read type definitions in JavaScript.

When None Is Not None: Tracking a Cookie Corruption Bug in Requests
Root cause analysis of a decade-old bug in psf/requests where setting a cookie value to None corrupts the entire Cookie header. Fix: 4 lines in cookiejar_from_dict(). Tests: 597 passed.
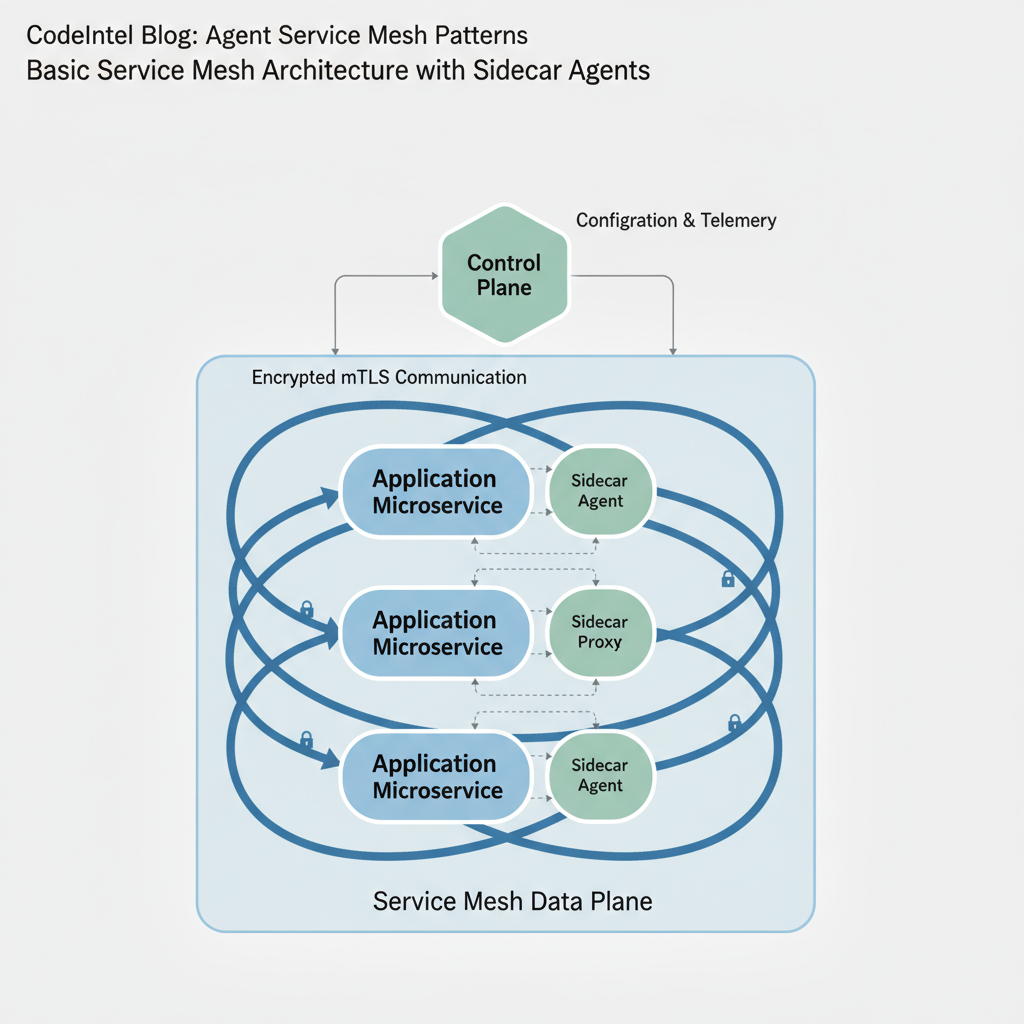
The Agent Service Mesh: Production Patterns for Inter-Agent Communication and Governance
Just as service meshes solved microservice-to-microservice communication at scale, agent meshes solve agent-to-agent communication. This essay examines the A2A protocol, Microsoft's Agent Governance Toolkit, and the architectural patterns for production inter-agent infrastructure.

Automated Git Bisect: From Manual Debugging to CI-Integrated Regression Hunting
A practical guide to automated git bisect with bisect run scripts, flaky test handling (majority voting, Bayesian inference with Git Bayesect), CI integration in GitHub Actions, and a portable bash toolkit you can drop into any repo.

Cookiecutter #2219: When One Bad Override Silently Kills the Rest
A 7-line fix in cookiecutter/generate.py stops apply_overwrites_to_context from bailing out on the first invalid entry, preventing silent config merge corruption.

TypeScript Error Handling: 4 Patterns Tested Against Production Failures
A comparison of try/catch with `unknown`, the Go-inspried tuple pattern, neverthrow's Result type, and TypeScript-zod safeParse. Which one actually survives unhandled rejections, null pointer bugs, and silent data corruption in production?

Build Custom ESLint Rules to Enforce Codebase-Specific Patterns
A practical guide to writing, testing, and shipping custom ESLint rules with autofix. Covers AST visitors, RuleTester, flat config, and real-world examples from TypeScript codebases.
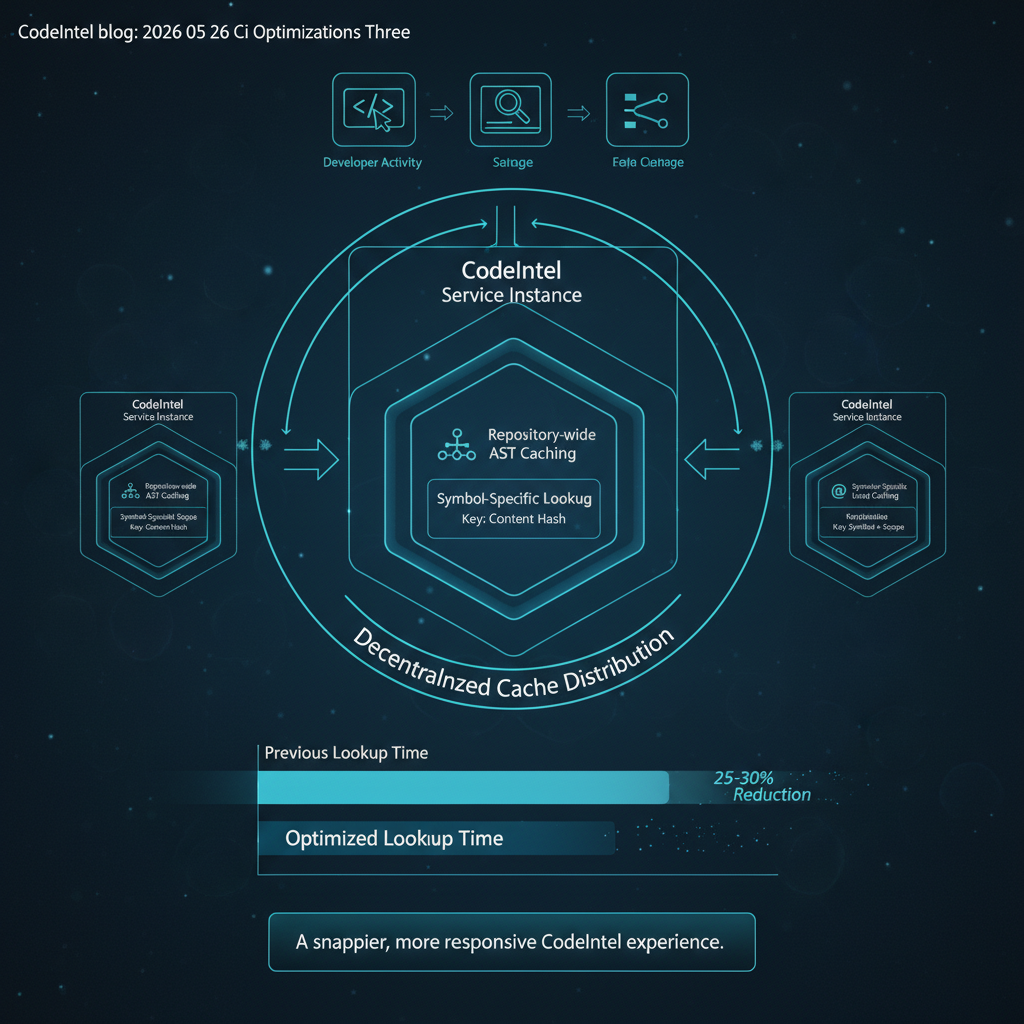
Three CI Optimizations That Cut Python Test Execution by 81%
Trail of Bits cut PyPI's test suite from 163s to 30s. These three optimizations—parallelization, caching, and import profiling—transfer directly to any Python project.
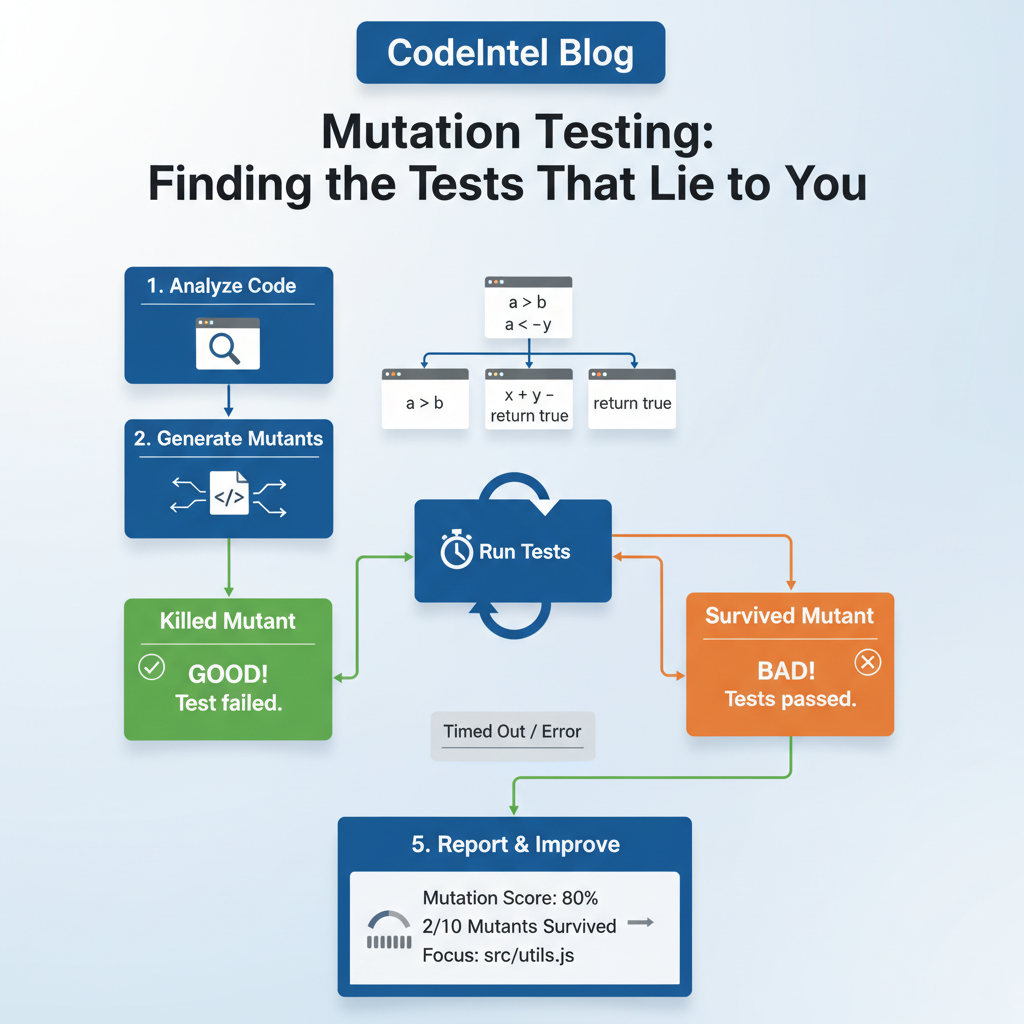
Mutation Testing: Finding the Tests That Lie to You
The mutmut cache output shows 3 mutants survived from 76 killed, illustrating that mutation score is a meta-test validating test rigor, not a replacement for other tests. Common survivors include condition flips (e.g., `if not is_member`) and arithmetic removals. Start with one module, scan for unasserted calls, and raise break thresholds incrementally. The final key takeaway: mutation testing is the only metric that validates test correctness.
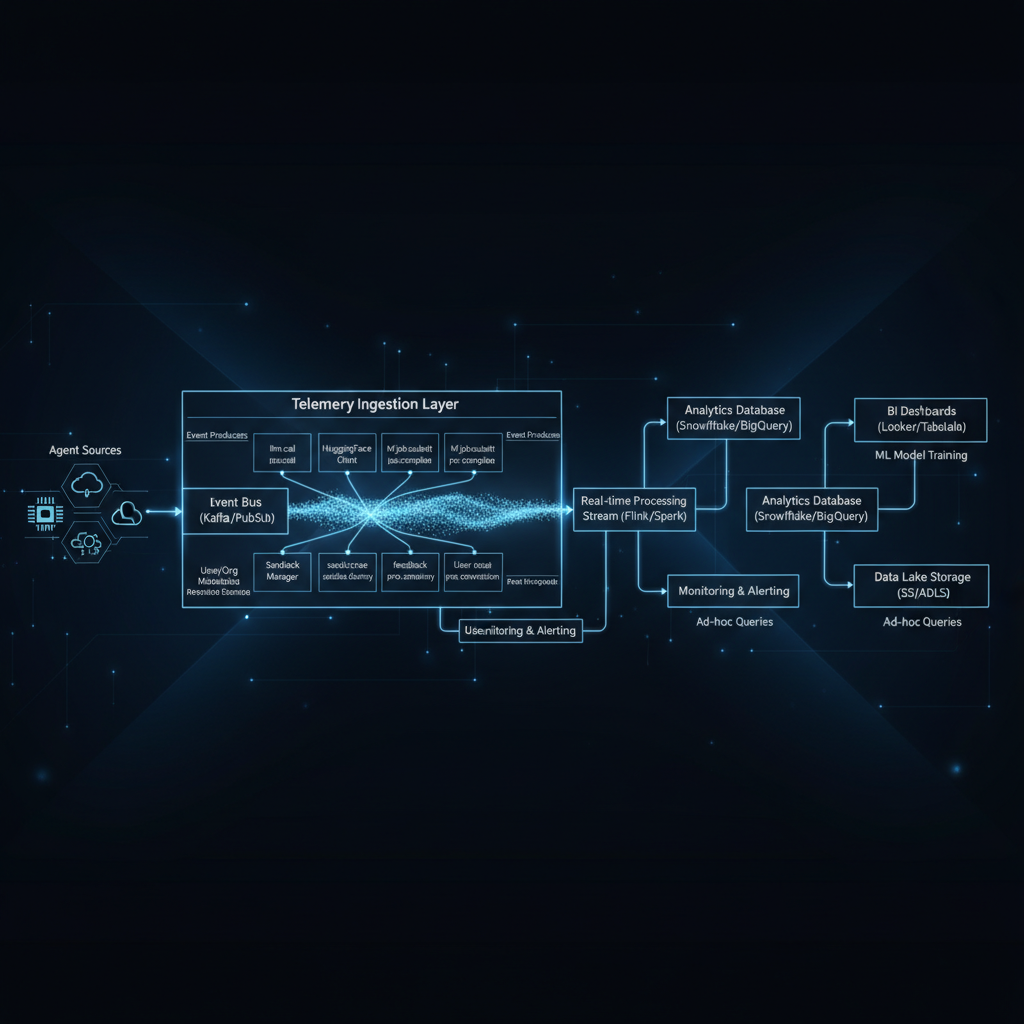
Building an Agentic Telemetry System: Lessons From HuggingFace's ML Intern
The telemetry system logs events via session.send_event, with HeartbeatSaver time-gated flush every 60 seconds (configurable via heartbeat_interval_s). Agent turns can last minutes, requiring mid-turn heartbeat saves. The 200-line module uses one-liner callsites and best-effort try/except. Cost is tracked by kind tags (main, research, compaction). Extract_usage normalizes Anthropic/OpenAI cache tokens. Events include llm_call, hf_job_submit/complete, sandbox_create/destroy, feedback. JSONL lo...
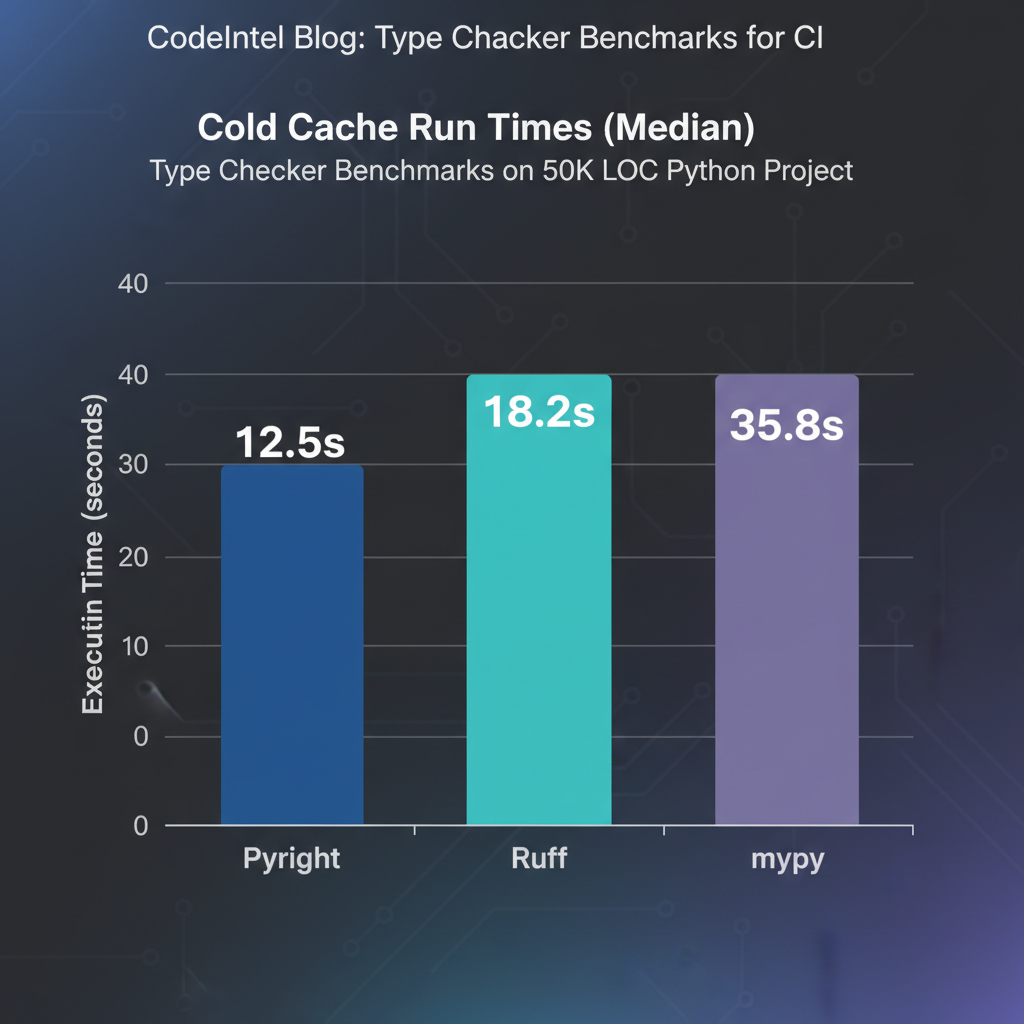
Type Checker Benchmarks for CI: Pyright vs mypy vs Ruff
Benchmarks mypy, Pyright, Ruff on 50K-line Django. Cold start: Ruff 0.8s, Pyright 6s, mypy 28s (ephemeral CI bottleneck). Incremental: Pyright daemon 1.5s beats mypy cache 8s. Mypy deepest (--strict weekly); Pyright 95% with report*; Ruff preview skips complex. Recommendations: small Ruff, medium Pyright, large two-stage (85% savings). Sample CI: actions/checkout, setup-node. Quick fix: measure, add Ruff, replace mypy, schedule mypy --strict, controlled rollout. Key takeaway: mypy depth king,...

CodeClash: SWE-Bench Team Drops ELO-Based Coding Eval Where AIs Fight in Games
CodeClash, a SWE-bench benchmark, ranks models via six adversarial games using opponent-weighted ELO. It tackles contamination, adversarial measurement, and strategy—prompting OpenAI to drop SWE-bench Verified. Top ELO: Claude Sonnet 4.5 (1385), GPT-5 (1366), o3 (1343); just 19 points separate them. Per-arena: Halite o3 1577, Poker GPT-5 1599, CoreWar Claude 1641. A 175-point gap follows. The leaderboard lacks trajectories, logs, cost data and is locked to Nov 2025. CodeClash joins the SWE-be...

What VS Code's Coding Harness Teaches About Agent Evaluation
The VS Code harness rebuilds context with system message, workspace, editors, history, tool results, memory. Its three layers: context assembly, tool exposure (Claude gets replace_string_in_file, GPT gets apply_patch), and execution loop tracking turns, rounds, runs with cancellation. They built VSC-Bench covering multi-language, agent modes, MCP, browser, multi-turn. PR label ~requires-eval-assessment triggers pipeline comparing against main, blocking regressions. Quote: harness defines blan...
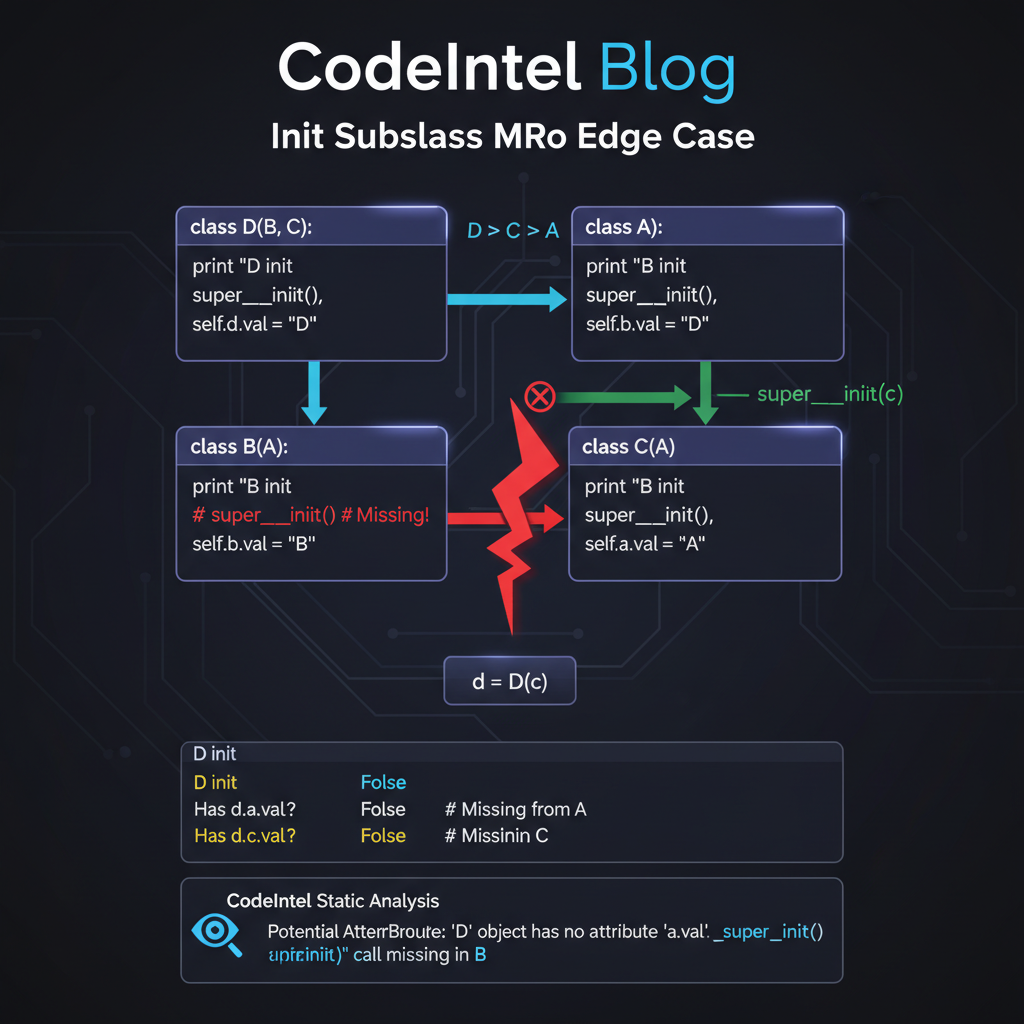
When __init_subclass__ Goes Silent — A CPython MRO Edge Case
Python's __init_subclass__ hook silently fails when a metaclass mro() places Superclass before subclass (CPython bug #105038, reported by plokmijnuhby).…

Python `__del__`: Three Silent Failure Modes You'll Regret Ignoring
Python's __del__ has three failure modes: silent swallowing (exceptions to stderr), resurrection (anti-pattern with FINALIZED flag in gcmodule.c), and shutdown crashes (module globals become None). PEP 442 (Python 3.4) fixed pre-3.4 gc.garbage leaks via tp_finalize. The industry fix is weakref.finalize (no self, bounds checked) for non-deterministic cases and context managers for deterministic ones. Production incidents include ulimit from open files, OOM from resurrected ORM sessions, and co...

SWE-Bench Verified Is Dead — Long Live SWE-Bench Pro
OpenAI stopped reporting SWE-Bench Verified after auditing 138 problems with six or more engineers; 35.5% had narrow tests (e.g., pylint task importing exact function name) and 18.8% wide tests, totaling 59.4% flawed. Contamination was confirmed: Gemini 3 Flash reproduced the django__django-11099 diff from its ID. The replacement, Scale AI's SWE-Bench Pro, has 1,865 tasks from 41 repositories, averaging 107 lines changed. On it, Claude Opus 4.5 scores 45.9% with standardized scaffolding, but ...

Python Metaclass Inheritance Pitfalls: When C and Python Metaclasses Collide
Combining C and Python metaclasses triggers TypeError when C tp_new uses MRO to invoke Python __new__. Constraints: safe tp_new chaining and tp_basicsize. Fixes: reorder bases (Python metaclass first) or modify C tp_new to call tp_base->tp_new (skips Python __new__). Increasing tp_basicsize ensures correct base selection. First reported 2004, affects ZODB, SQLAlchemy; a silent hazard. Key takeaway: never let C tp_new invoke Python __new__; prefer composition; document tp_basicsize requirement...

POSIX `--` Separator: Fixing Ripgrep's Filename Argument Confusion
How the `--` separator prevents compression tools from misinterpreting filenames as options, with a fix PR analysis from ripgrep.

Python Context Managers in Production: ExitStack, Async, and Testing Patterns
Production-ready context manager patterns beyond basic with statements — ExitStack composition, async cleanup, and pytest fixture integration with real code templates.

Fixing `__slots__`: Safe Metaclass Patterns to Avoid Attribute Conflicts
Resolving the `__slots__` class variable conflict with robust metaclass design, using Python data model rules and PEP references.

Python `__slots__`: Memory Optimization or Silent Pitfall?
Exploring the nuanced behavior of `__slots__` in Python, including memory implications, performance gains, and how they interact with metaclasses.
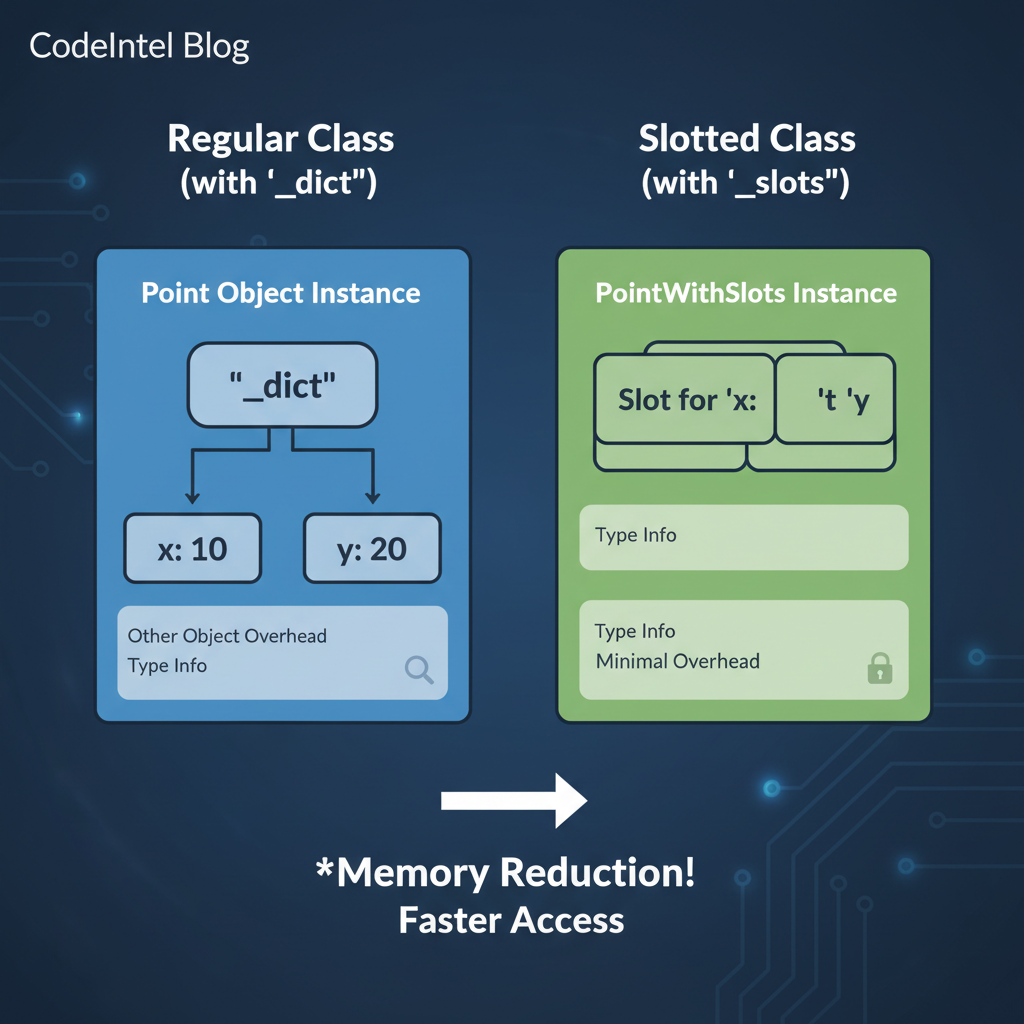
Understanding `__slots__` with Metaclasses in Python
Exploring advanced behavior of `__slots__` via metaclasses, including memory implications and inheritance rules.

Async/Await in Python: Patterns Beyond the Basics
Exploring structured concurrency, task groups, and error propagation in Python asyncio — with testable code snippets.

SWE-bench Proxy: Baseline — 80% Real-World Bug Fix Rate
Measuring coding intelligence with real GitHub bug fixes. Baseline: 80% real-world bug fix rate on 31 instances from 4 repos.
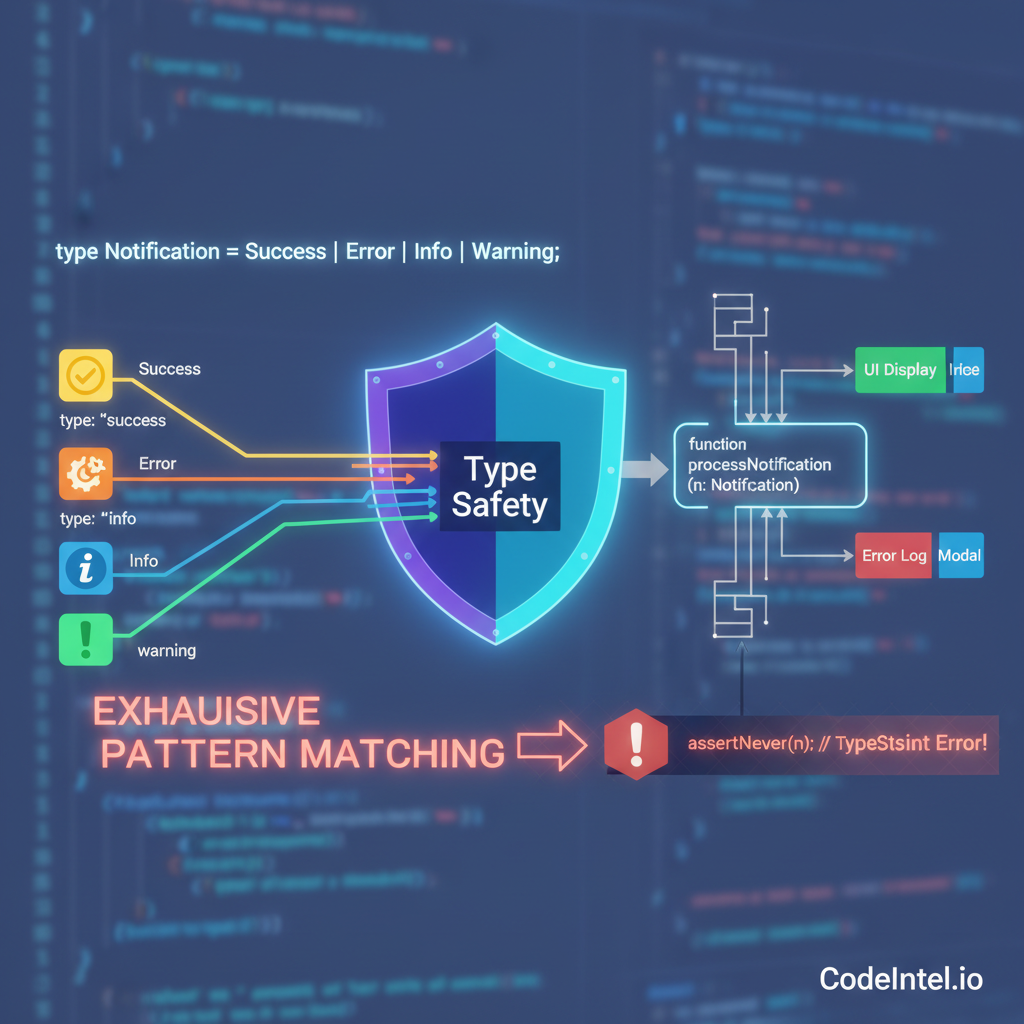
TypeScript Discriminated Unions: Exhaustive Pattern Matching
A practical guide to TypeScript discriminated unions with exhaustive pattern matching, the never type, and real-world detection patterns for your codebase.

Asyncio Queue: Timeout Behavior and Error Handling
A practical guide to asyncio.Queue timeout behavior, error handling with QueueFull/QueueEmpty, graceful shutdown patterns, and detection techniques for production async code.

Bash Error Handling: What Happens When You Forget set -e
A practical guide to Bash error handling with set -euo pipefail, trap ERR for guaranteed error catching, subshell pitfalls, and detection patterns for production shell scripts.