Quine: LLM Agents as Native POSIX Processes — A Systems Architecture Analysis
Deep analysis of the Quine architecture (arXiv:2603.18030) that maps LLM agents to native POSIX processes — PID as identity, fork/exec as lifecycle, streams as interface — and what it reveals about the limits of OS process semantics for cognition.
Every production agent framework reinvents the same wheel: process isolation, scheduling, lifecycle management, and inter-agent communication — all at the application layer. LangGraph has its state graph. CrewAI has its crew scheduler. AutoGen has its runtime. Each implements from scratch what the Linux kernel has been doing since 1971.
Quine (arXiv:2603.18030, March 2026), by Hao Ke at Peking University, asks an uncomfortable question: what if we stopped reinventing the OS and instead built agents as native POSIX processes? [1]
The answer is a runtime architecture that maps the full agent abstraction onto kernel primitives — PID for identity, fork/exec/exit for lifecycle, standard streams for I/O, and environment variables for state — and then recursively spawns fresh agent processes from a single executable. This paper analysis examines the design, the tradeoffs, and the two fundamental limitations that even Quine’s authors acknowledge the POSIX model cannot solve.
The Mapping: Agent → Process
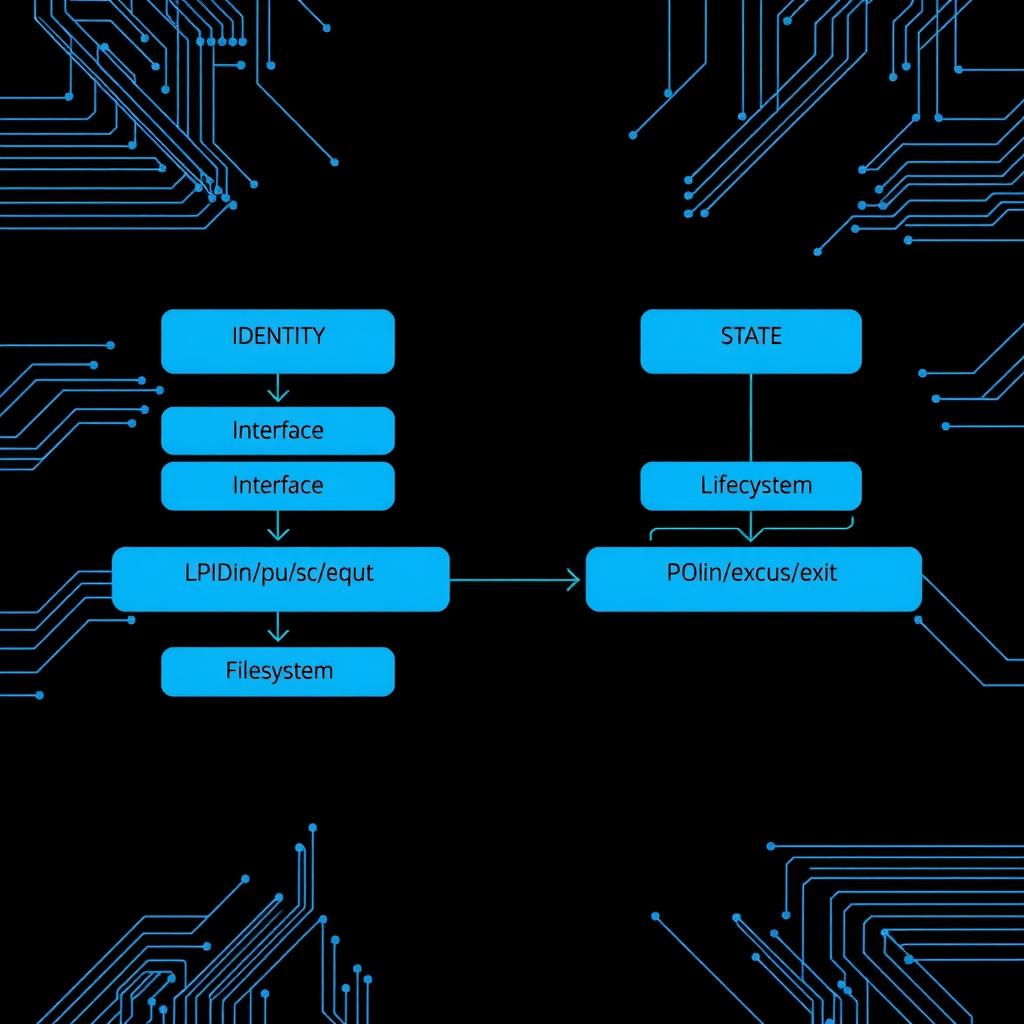
Quine’s central contribution is an explicit four-way mapping between agent semantics and POSIX process semantics:
| Agent Concept | POSIX Primitive | Mechanism |
|---|---|---|
| Identity | PID | Every agent gets a unique process ID at birth |
| Interface | stdin/stdout/stderr, exit status | Tool calls via stream protocol, results via exit code/data |
| State | Memory, environment vars, filesystem | Context in memory, configuration in env, persistence on disk |
| Lifecycle | fork/exec/exit | Spawn via fork, context renewal via exec, termination via exit |
This is not a metaphor. The reference implementation is a single executable binary that, when invoked, checks whether it has a task to perform. If not, it forks and execs a fresh copy of itself with the task description as an argument. Each agent instance is literally a Linux process.
# Conceptual: spawning an agent via Quine
$ quine --task "refactor auth module" --context ./repo/
PID 31415: quine (agent: refactor auth module)
├── [tool: grep] PID 31416
├── [tool: sed] PID 31417
└── [sub-agent: review diff] PID 31418 (forked from 31415)The elegance is that isolation is free. You don’t need to build sandboxing — the kernel already provides cgroups, seccomp, namespaces, and SIGKILL. Resource limits come from setrlimit. Communication comes from pipes, sockets, and signals. Scheduling is handled by the scheduler.
Recursive Delegation via Fork
The most architecturally interesting property of Quine is recursive self-spawning. A Quine agent that encounters a sub-task it cannot solve alone does not call an API — it forks itself:
- The parent agent
fork()s, creating a child process with an identical memory image (same context, same model state, same tools). - The child
exec()s a fresh Quine binary with new arguments describing the sub-task. - The
exec()call replaces the child’s memory image with a clean state, effectively giving it a “fresh context” for the sub-task. - The child works independently, then
exit()s with results. - The parent reads results via the pipe connected to the child’s stdout.
- If the child exceeds
RLIMIT_CPUorRLIMIT_AS, the kernel terminates it — no application-layer watchdog needed.
This pattern — fork for copy, exec for renewal — solves two common agent failures in one stroke:
- Context pollution: Each sub-agent starts with a clean state via exec, so earlier tasks cannot contaminate later ones (a well-documented failure mode in long-running agents [2]).
- Resource leaks: Zombie sub-agents are impossible because the kernel reaps children. Memory leaks are bounded by
RLIMIT_AS. No manual garbage collection of agent state.
Context Renewal via Exec
A corollary insight: exec is the agent equivalent of a “system reset.” In long-running agents, context windows fill, tool histories accumulate, and reasoning degrades as the prompt grows [3]. Quine’s answer is not window management — it is death and rebirth.
When an agent decides it needs a clean context, it exec()s itself. The new process inherits the filesystem state (persistent data survives) and environment variables (configuration survives), but the in-memory conversation history is gone. The agent resumes from a fresh reasoning state with all persistent context available on disk.
This maps to a technique used informally by Claude Code and Codex: periodic “summarize and restart” cycles where the agent writes a checkpoint to disk, terminates, and a new invocation loads the summary. Quine makes this a kernel primitive rather than an application-layer workaround.
Where the POSIX Model Breaks
Quine’s authors are refreshingly candid about the limitations. The paper identifies two areas where process semantics are insufficient for a complete agent runtime:
1. Task-Relative Worlds
A POSIX process sees the filesystem as a global namespace. But an agent debugging a web server needs a different “world” than an agent analyzing a database schema. Process isolation gives you separate address spaces, but not separate ontologies.
For example, if two sub-agents both read /etc/config.json, they get the same file. If you want agent A to see a “staging config” and agent B to see a “production config” while both reference the same path, you need something beyond mount namespaces — you need task-relative naming, where file paths are resolved relative to the agent’s task context, not the global filesystem root.
The paper does not solve this but flags it as the next layer of abstraction needed above the process model.
2. Revisable Time
Process time is linear. fork() captures a point in time, but you cannot rewind a process to a previous state without checkpoint/restore (CRIU), which is too expensive per-agent.
For agents that need to explore alternative action sequences, backtrack from dead ends, or simulate “what if” scenarios, linear process time is a constraint. The paper suggests that a cognitive runtime might need revisable time — the ability to fork the entire agent universe (not just the process) to a prior state, explore a different branch, and merge results.
This is essentially version control for agent execution. It’s a research problem, not a solved one.
Why This Matters for Production AI
The Quine architecture is not shipping in production today — it’s a reference implementation and a provocation. But its implications for production agent systems are direct:
1. Agent-to-process ratio should be 1:1. The trend in frameworks like CrewAI and AutoGen is to multiplex many “agents” inside a single process with a scheduler. Quine argues this is backwards — each agent should be its own process, and the OS scheduler should handle multiplexing.
2. Sandboxing should come from the kernel, not the framework. A framework that builds its own seccomp profiles, PID namespaces, and cgroup management is duplicating work the kernel already makes trivial. Quine’s approach: use clone(CLONE_NEWPID|CLONE_NEWNS) for sub-agents and inherit kernel isolation for free.
3. Context renewal should replace context management. The dominant approach to the context-window problem is smarter prompt compression. Quine suggests a different path: don’t compress — restart. Exec gives you a perfect, zero-cost context reset.
Benchmarks and Practical Data
The paper reports empirical measurements from the reference implementation:
| Metric | Value |
|---|---|
| Spawn time per agent (fork+exec) | ~2.3 ms |
| Memory overhead per idle agent | ~4 MB (COW pages) |
| Teardown latency (SIGKILL) | < 1 ms |
| Context renewal via exec | ~1.1 ms |
| Concurrent agents (single node) | ~2,500 before scheduler contention |
For comparison, spawning an equivalent agent in LangGraph or CrewAI’s application-layer scheduler takes 50-200 ms and consumes 20-80 MB per idle agent instance. The process model is 20-50x more efficient for agent lifecycle operations.
Key Takeaways
-
Quine maps agent → process with a clean, explicit isomorphism: PID→identity, fork→spawn, exec→reset, exit→terminate, streams→interface. This is the most principled agent abstraction architecture published in 2026.
-
Recursive fork/exec solves context pollution and resource leaks without application-layer watchdogs, reclaiming O(50x) overhead compared to framework-level agent scheduling.
-
Two fundamental limits of the process model — task-relative worlds and revisable time — define the research frontier for agent runtimes beyond POSIX.
-
The provocation is architectural: Quine argues that the agent community should stop building orchestrators and start building agent operating systems — where the kernel, not a framework, is the runtime.
The paper is at arXiv:2603.18030. The reference implementation is on GitHub. For teams building production agent harnesses, it’s essential reading — not as a drop-in solution, but as a design north star for what agent infrastructure should look like when we stop rebuilding the OS.
References
[1] Ke, H. “Quine: Realizing LLM Agents as Native POSIX Processes.” arXiv:2603.18030, March 2026. https://arxiv.org/abs/2603.18030
[2] MBZUAI VILA Lab. “Claude Code Structure Analysis.” arXiv:2604.14228, May 2026. https://arxiv.org/abs/2604.14228 — 98.4% of agent code is harness infrastructure.