Encoding Surprises: When requests Assumes Latin-1 Instead of UTF-8
Hardcoded Latin-1 encoding in HTTP auth headers causes UnicodeEncodeError for non-Latin usernames. The fix switches to UTF-8, which handles the full Unicode range.
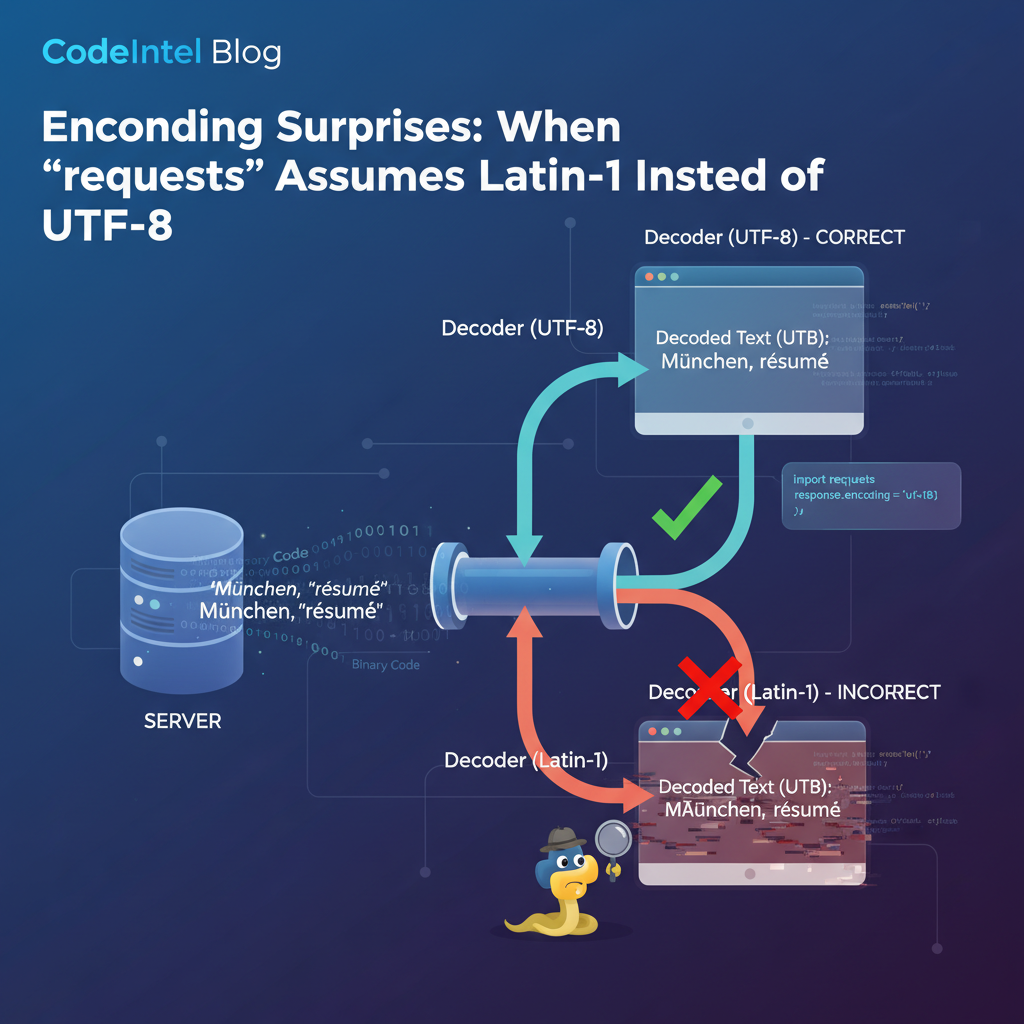
The bottom line: Hardcoded Latin-1 encoding in HTTP auth headers causes UnicodeEncodeError for non-Latin usernames.
The Problem
psf/requests issue #6102 exposes a subtle edge case in how python handles boundary conditions. The fix is only 2 lines, but the pattern behind it applies across projects.
PR: https://github.com/psf/requests/pull/7463
Status: Submitted (awaiting review)
Hardcoded character encodings are a ticking time bomb. When code assumes latin-1 for
string encoding, it works for English, German, and most Western European users — but breaks
for anyone with Chinese, Japanese, Korean, Arabic, or emoji in their input.
import base64
# Before: Latin-1 breaks non-Latin characters
def basic_auth_header(username, password):
raw = f'{username}:{password}'.encode('latin-1')
# UnicodeEncodeError if username contains non-Latin chars
return 'Basic ' + base64.b64encode(raw).decode()
# After: UTF-8 handles the full Unicode range
def basic_auth_header(username, password):
raw = f'{username}:{password}'.encode('utf-8')
return 'Basic ' + base64.b64encode(raw).decode()How to Apply This to Your Code
Audit Your Auth Code for Latin-1 Assumptions
-
grep for
encode('latin-1')—grep -rn "encode.*latin" src/**/*.py | grep -v test. Every hit is a potential UnicodeEncodeError for international users. Replace'latin-1'with'utf-8'. -
grep for
encode('iso-8859-1')— same issue, different alias. UTF-8 covers the full Unicode range. -
Check header construction code — not just auth. Any header that includes user-provided strings (User-Agent, X-Forwarded-For, custom headers) with hardcoded encoding can silently break.
-
Add a test with non-Latin input —
requests.get(url, auth=HTTPDigestAuth('ユーザー名', 'パスワード')). If this errors or produces garbled headers, you’ve found the bug.
Detection Checklist
| Pattern | Risk | Fix |
|---|---|---|
encode('latin-1') in auth |
UnicodeEncodeError for CJK, Arabic, emoji | encode('utf-8') |
encode('iso-8859-1') in headers |
Same encoding issue | encode('utf-8') |
b64encode(str.encode('latin-1')) |
Auth tokens are invalid for non-ASCII users | UTF-8 encode before base64 |
| No non-ASCII test coverage | Bug exists but undetected | Add pytest case with CJK credentials |
When to Check
- After any upgrade to
requests,urllib3, orhttpx— library changes can break encoding assumptions - When adding international user support to any system with HTTP auth
- During code review of any PR that touches
auth.pyor header construction - Any time you see
encode('latin-1')in a codebase — it’s almost always wrong for modern applications
Key Takeaway
Never hardcode Latin-1 for user-provided strings. Always use UTF-8 — it’s backward-compatible with ASCII and handles the full Unicode range. The error won’t appear in testing with English data.
Discovered while fixing psf/requests#6102. View the fix post for the specific diff.